AI-Assistant als Edge-Adapter
ServiceDeskLite hat einen Intake-Assistenten bekommen: Der Nutzer beschreibt sein Problem in Freitext, ein Claude-Modell entscheidet per Tool Calling, ob es ein Ticket anlegt oder ein bestehendes korrigiert, und die Antwort erscheint Token für Token im Browser. Für sich genommen ein überschaubares Feature. Interessant wird es an der Stelle, an der es die Architektur berührt: Ein externer Dienst, dessen Antworten nicht vorhersagbar sind, soll Domain-Zustand verändern dürfen — und seine Ausgabe kommt als Stream, der mit möglichst wenig Verzögerung beim Client ankommen soll.
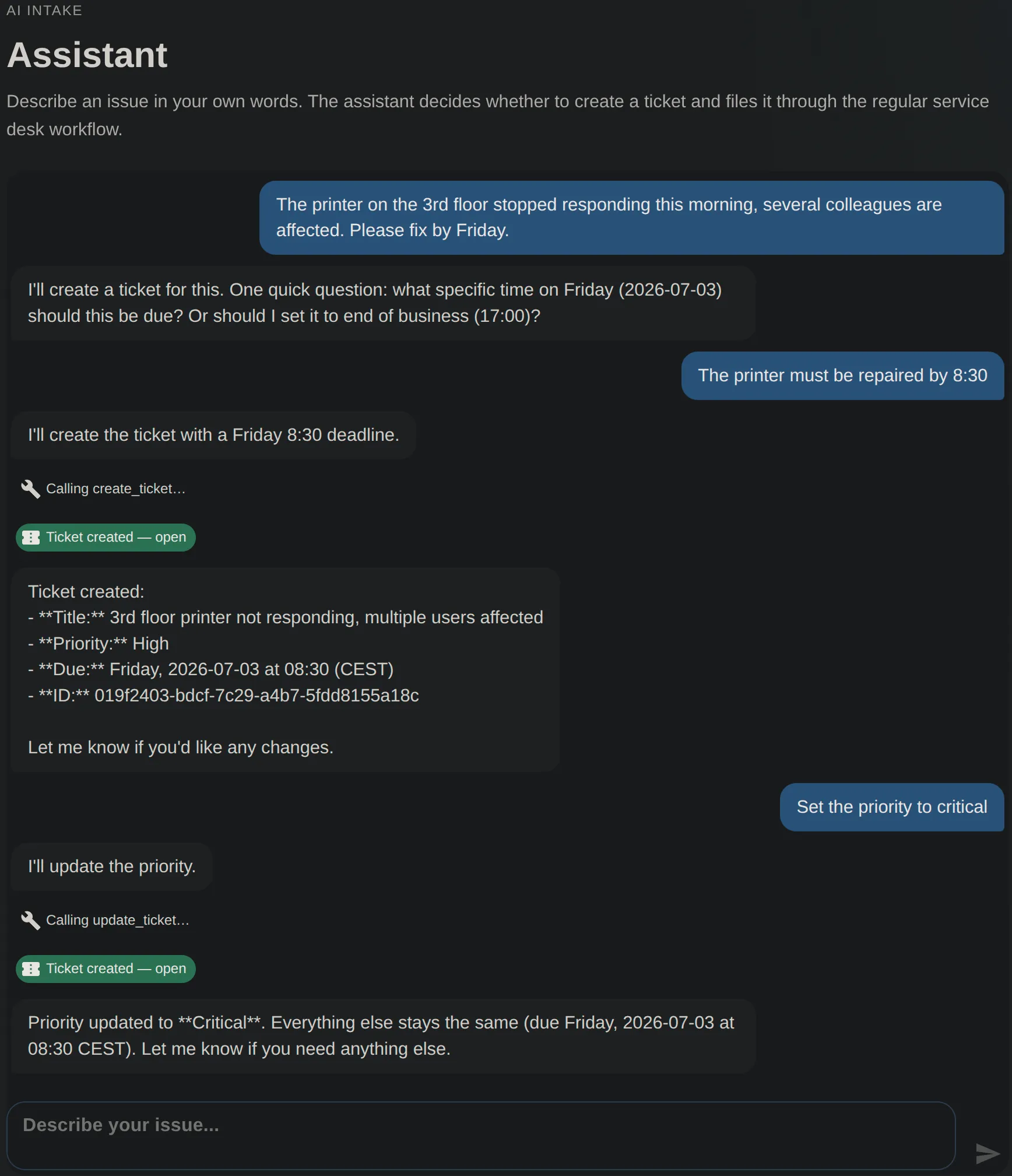
Die Frage, die das ADR beantwortet, ist deshalb weniger „wie baut man das” als „wo gehört so etwas hin”.
Drei Kandidaten
Der naheliegende Ort wäre ein Application-Port: IAssistantService, Implementierung in Infrastructure, symmetrisch zur Persistence. Das Muster ist vertraut, und für Persistence funktioniert es gut. Hier passt die Symmetrie aber nicht ganz: Ein Repository kapselt etwas, das mehrere Use Cases brauchen. Der Assistent hat genau einen Konsumenten — den Endpoint, der ihn exponiert. Dazu kommt das Streaming: SSE-Framing und das Zusammensetzen partieller Antworten müssten durch die Abstraktion hindurchgereicht werden, die dadurch eher breiter als sauberer würde.
Ein eigener Service daneben wäre die andere Richtung — sauber getrennt, aber ein zweites Deployment für einen einzelnen Endpoint. In einem Referenzprojekt schwer zu rechtfertigen.
Bleibt die dritte Option: ein Edge-Adapter im API-Projekt. Die LLM-Orchestrierung lebt neben dem Endpoint, der sie sichtbar macht. Die Begründung ist dieselbe, mit der das Projekt schon auf MediatR verzichtet hat: Eine Abstraktion mit einem einzigen Konsumenten bringt ihre Kosten sofort, ihren Nutzen erst, wenn ein zweiter dazukommt. Der Weg dorthin bleibt offen.
Der Weg in die Domain
Wie erreicht das Modell die Domain? Über denselben Weg wie alle anderen: Die Tools, die das Modell aufrufen kann, rufen ihrerseits die bestehenden Command-Handler auf — dieselben, die auch hinter den REST-Endpoints stehen. Es gibt keinen Sonderpfad.
Das klingt unspektakulär, trägt aber weit. Jedes KI-erzeugte Ticket durchläuft dieselbe Validierung, landet im selben Audit-Trail und im selben Outbox-Staging wie ein von Hand erzeugtes — ohne dass dafür etwas doppelt gebaut wurde. Die Frage, ob die Business-Regeln auch für die KI gelten, stellt sich damit nicht mehr; es gibt schlicht keinen Pfad, auf dem sie umgangen werden könnten.
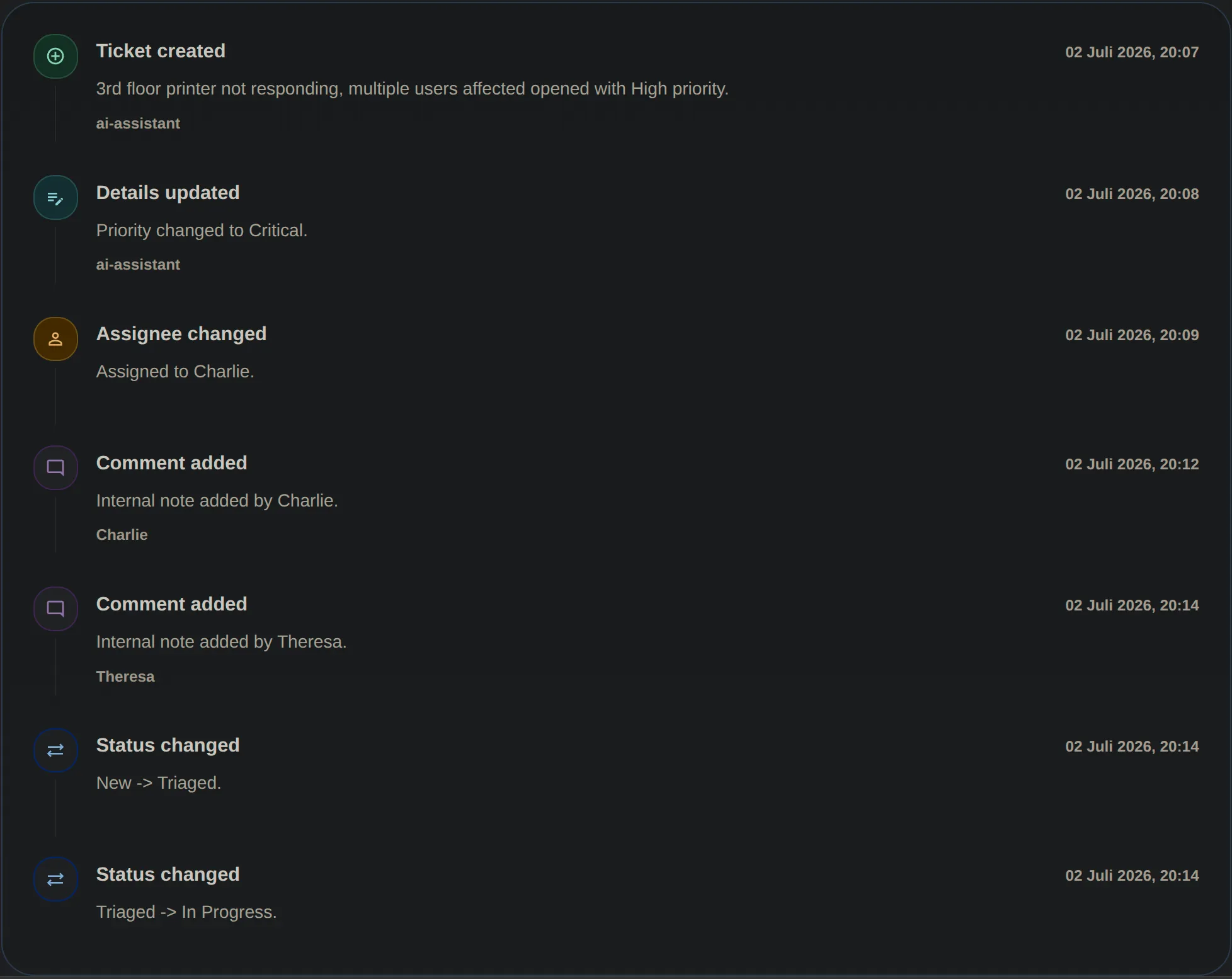
Domain und Application kompilieren ohne jede Anthropic-Referenz. Ließe man das Feature wieder fallen, wären ein Ordner, eine Endpoint-Gruppe und ein DI-Aufruf zu entfernen.
Tool-Aufrufe sind Eingaben
Ein Tool-Aufruf vom Modell ist strukturell dasselbe wie ein HTTP-Request von außen: JSON, das gültige Argumente enthalten sollte — es aber nicht muss. Also wird er auch so behandelt: geparst und geprüft, bevor er einen Handler erreicht. Stimmt die Form, sind die Enum-Werte bekannt, liegt das Fälligkeitsdatum in der Zukunft.
Bei einer Ablehnung geht der Fehler als Tool-Ergebnis zurück an das Modell, das im selben Gespräch einen korrigierten Versuch machen kann. Aus der Prüfung wird so eine Rückkopplung: Das Modell bekommt die Gelegenheit, sich selbst zu korrigieren, statt dass ein fehlerhafter Wert still im System landet. Die Schleife hat eine feste Obergrenze an Durchläufen — für den Fall, dass ein Versuch dem nächsten gleicht.
Ein angenehmer Nebeneffekt: Parsing und Prüfung sind Funktionen ohne Seiteneffekte. Sie lassen sich mit gewöhnlichen Unit-Tests abdecken, ohne API-Key und ohne Netz.
Streaming bleibt Präsentation
In der Antwort des Modells liegen zwei Dinge verschränkt: Text, der sofort zum Browser soll, und Tool-Argumente, die als JSON-Fragmente eintreffen und erst am Ende eines Blocks vollständig sind. Man könnte daraus zwei Verarbeitungswege machen. Es reicht einer: Text wird im Moment des Eintreffens weitergereicht, Tool-JSON pro Block gesammelt und am Blockende geparst — ein Durchlauf für beides.
Dass all das im API-Layer liegt, ist die Platzierungsentscheidung konsequent zu Ende gedacht: Token-Auslieferung und SSE-Framing sind Präsentationsbelange. Ein Application-Layer, der wissen muss, was ein Server-Sent Event ist, hätte die Trennung bereits aufgegeben.
Ein Detail am Rand: Die API hält keinen Gesprächszustand. Jeder Turn schickt das volle Transkript erneut; der Server steuert pro Anfrage nur das aktuelle Datum samt Wochentag und die Zeitzone des Nutzers bei. Das wirkt klein, entscheidet aber darüber, ob „bis Freitag früh” auf dem richtigen Tag landet — ein Modell ohne Kalender kann das nur raten.
Was bewusst fehlt
Kein Application-Port, solange es keinen zweiten Konsumenten gibt. Keine Konversations-Persistenz — Transkripte leben in der Browser-Session. Kein generischer Tool-Plugin-Mechanismus — bei zwei Tools sind zwei explizite Klassen leichter zu lesen als eine Registry. Jedes dieser Dinge ließe sich später ergänzen; keines davon würde heute etwas verbessern.
Wann überdenken
Drei Auslöser sind im ADR festgehalten. Ein zweiter Konsument des Assistenten — ein Bot, ein Background-Job — wäre der Punkt, an dem der Application-Port seinen Nutzen bekommt. Sollen Gespräche über Sessions hinweg fortgesetzt werden, wandert der Zustand auf den Server, und der Vertrag ändert sich mit. Und wächst die Zahl der Tools über eine Handvoll, beginnt sich der Registry-Mechanismus zu lohnen, der heute nur Aufwand wäre.
Bis dahin bleibt es bei der Linie, auf die alle Teilentscheidungen einzahlen: Das Modell bleibt außerhalb der Architektur. Das macht den Assistenten nicht klüger — aber es sorgt dafür, dass seine Fehler als abgelehnte Anfragen enden und nicht als fehlerhafter Zustand.